Attending Redis Day NYC 2019
— June 28, 2019I attended the full-day conference at Redis Day NYC yesterday. All the talks were related to user stories and developer updates from the Redis community. Here are my notes and takeaways from the conference:

Redis 6 - Salvatore Sanfilippo, creator of Redis
tldr: keynote; upcoming Redis 6 features;
Features that were discussed during the talk:
- User-facing:
- ACLs: At the moment, there is no control over destructive commands like
FLUSHALLandDEBUG SEGFAULT. Traditionally, these commands are renamed to something unguessable to prevent anyone from executing them. ACLs could help solve this problem. - RESP3 (a new Redis protocol): e.g. Support for a key-value type response.
- Redis Cluster Tools and SSL.
- ACLs: At the moment, there is no control over destructive commands like
- Internal:
- Threaded I/O, Modules APIs, a new
EXPIREalgorithm
- Threaded I/O, Modules APIs, a new
- Outsiders:
- Project 1: Redis Cluster Proxy. Community struggled to use client with redis cluster.
- Project 2: Disque module: a message broker. Similar to Amazon SQS rather than Kafka.
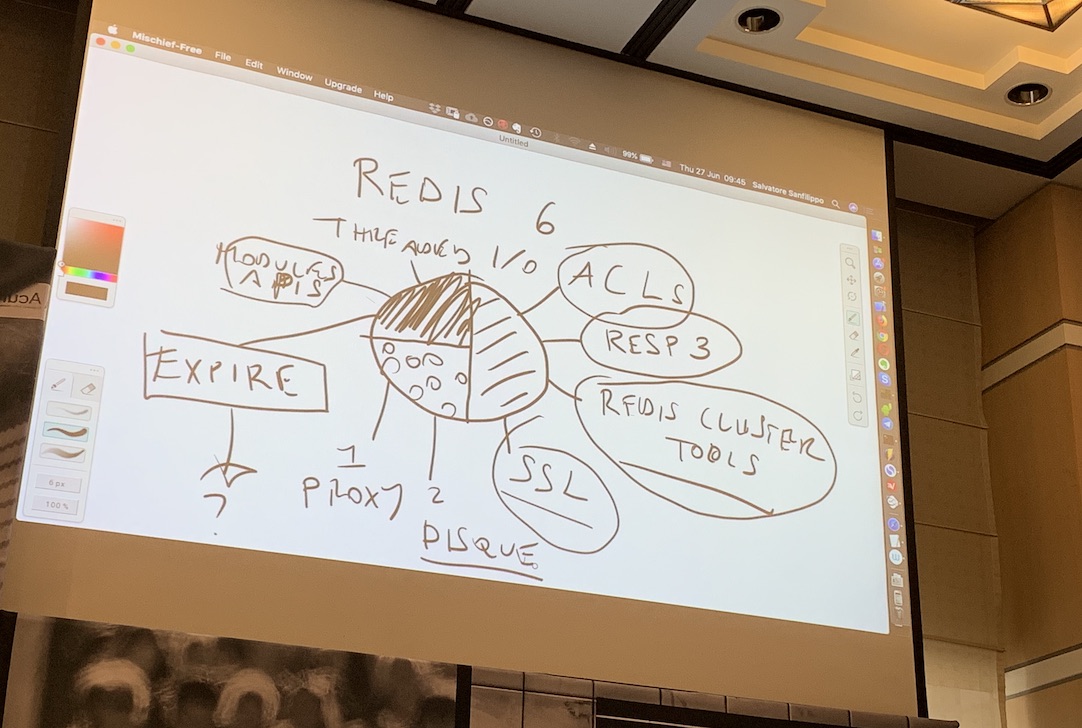
Perhaps we’ll see a new version of Redis sometime the end of this year or early next year, IIRC.
Redis Reliability, Performance & Innovation - Yiftach Shoolman, Redis Labs
tldr: lots of numbers; marketing for Redis Enterprise;
Takeaways:
- Conflict-free replicated data types (CRDTs): a data structure which can be replicated across multiple containers in a network, such that the replicas can be updated independently and concurrently without coordination, and it is always mathematically possible to resolve inconsistencies. Looks like an interesting thing to look into…
- RedisGears: a Redis module that adds a serverless engine. Seems like the trend for databases is moving towards “serverless” technologies…

Solving Problems at Scale with Redis - Jon Hyman, Braze
tldr: a talk about an internal incident; replaced existing solution with Redis to solve it;
Takeaways:
- Application Performance Index (Apdex): Like SLAs, but provides a holistic overview on how an application is performing. Buckets requests into three: satisfied, tolerating, and frustrated. Calculate score based on number of requests in each bucket.
- Refresh-ahead caching: Detect that the cache will be expiring soon, and attempt to update to prevent a cache miss in the future.
- Stampeding Herd problems: Massive concurrency that could bring the system down (e.g. cache stampede).
How Shopify is Scaling Up its Redis Message Queues - Moe Chaieb, Shopify
tldr: single tenants pushing Redis limits; case-by-case solutions; nice diagrams;
Case-by-case solutions:
- Error reporting: Kafka
- Connections: Proxy (e.g. Istio)
- Locking: Dedicated Redis Instance
- Queues: Horizontal Scaling / Dedicated Redis Instance
Did not take much notes in this talk since I interned at Shopify back then, and most stuff were familiar.
From Key-value to Multi-model - Guy Korland, Redis Labs
tldr: exploring various Redis modules and linking them together; everything is based on the key-value store;
- Talk: https://www.youtube.com/watch?v=dWmXd0-v8yo
- Slides: https://www.slideshare.net/gkorland/from-keyvalue-to-multimodel
- Project: https://github.com/RedisGears/MultiModelExample
It looks like Redis has many plug-and-play features which can be connected. Really cool!
Redis – A Quantitative Trader’s Perspective - Mauro Calderara, Citadel
tldr: unconventional use patterns; fork project and update; solid presentation;
Use case 1: Using redis as an API to transient data
- Redis lifetime bound to processes life-time, relatively short-lived.
- Clients coordinate via the redis instances.
- Sharding, erasure coding, fail over, load balancing, and eviction handled client-side.
Use case 2: Using redis as a parameter server in ML applications
- Coordinate embarrassingly parallel / map-reduce like computations.
- Can do advanced math on the parameter server using redis modules.
Use case 3: Using redis as a dyanmically scaling cache
- Redis associated with each worker contributing bandwidth to cache.
- Coordination via centralized redis.
- Fixed ratio of workers/cache leads to horizontal scalability.
Takeaway: One can also think of redis as more of a protocol and library than a service.
Redis has implemented a very nice box of network, scheduling, data structures, persistence, replication, and expiration parts that are generic, and one could embed complicated logic through custom modules.
That’s all for now. Looking forward to DashCon in Mid-July!