Lexical Analysis with ANTLR v4
— February 16, 2017I was trying to learn how a database engine is actually implemented, and I feel that the best way to do so is to try to build one myself. After days of readings, it seems that the first thing to do is to build a query parser which takes in SQL text and produces a parse tree which can be sent to the query optimizer or processor.
Conceptually, an interpreter or a compiler operates in phases, each of which transforms the code from one representation to another.
The diagram below shows the main phases taken for the front-end of the compiling process.
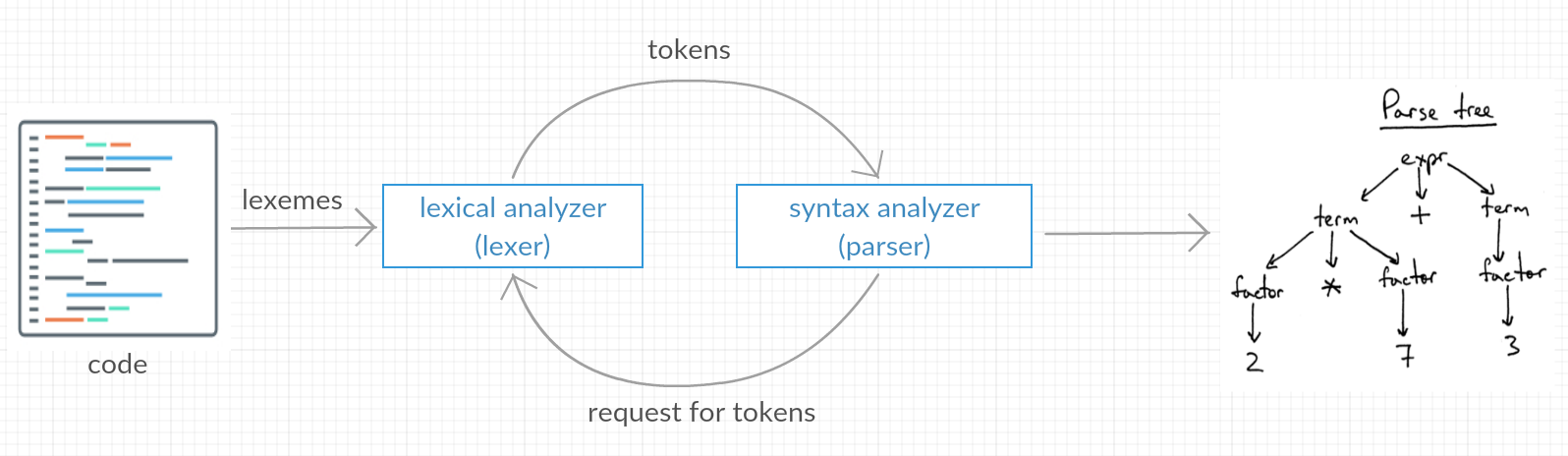
Lexical analysis, often known as tokenizing, is the first phase of a compiler. It is a process of converting a sequence of characters into a sequence of tokens by a program known as a lexer.
Lexers attach meaning (semantics) to these sequence of characters by classifying lexemes (strings of symbols from the input) into various types, and entries of this mappings are known as tokens. Consider this expression in the Scheme/Racket programming language:
(+ 3 (* 8 9))
For example, lexemes such as 3, 8, and 9, will be classified as the NUM token by the lexer. So after tokenization, the expression can be represented by the following table:
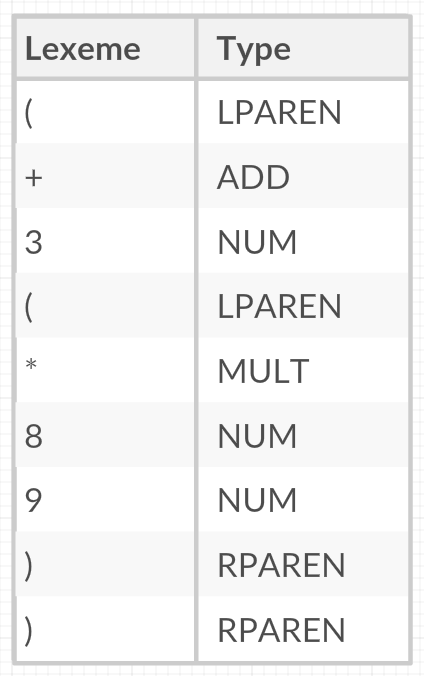
Observe that whitespaces are ignored during tokenization. Omitting tokens such as whitespaces, comments and new lines is really common in the process of lexing. However, in languages such as Python, where indentations are really important, there are special rules which are implemented in the lexer such as using INDENT and DEDENT tokens to determine which block does the code belong to.
If the lexer identifies that a token is invalid (i.e. not defined in the regular grammar of that programming language), it will generate an error. A lexer is generally combined with a parser, which analyzes the syntax of the code, and sometimes its semantics. Finally, a parse tree will be produced.
How Lexing Works?
To keep things simple, we use regular expressions to define the grammar of the language. We now have a notation for patterns that define tokens. But how do we evaluate these regular expressions without using the built-in regex matcher? What is the underlying data structure for a regular expression?
To implement the matching of these patterns, we will use finite state machines (FSM), commonly known as finite state automata.
Here is an example of FSM that accepts the regular expression (bb)*, i.e. even number of b’s.
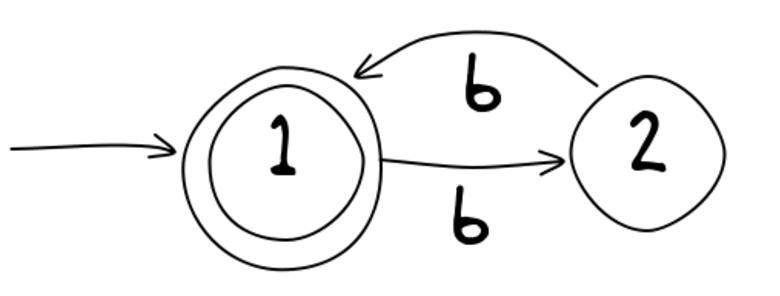
By evaluating an input string against the FSM, we can see whether it matches our regular expression (bb)*.
- If we are at state 1, the number of b’s seen so far is even.
- If we are at state 2, the number of b’s seen so far is odd.
- If we end at state 1, which is known as an accept state, it means that the FSM accepts the string and our string is in the right format. Then we can insert a new token entry.
However, implementing FSMs from regular expressions can be very tedious and error-prone. Imagine if we need to code FSMs for all the regular expressions that we have used to define our grammar.
Fortunately, we have tools that do this for us. These tools can either generate lexers or parsers, but they usually come together and are known as compiler-compilers. All we need to do is to use regular expressions to define the grammar of the language, and pass a grammar file to a lexer generator to get a lexer in a specific language (i.e. the programming language that we want to use to code our lexer).
Examples of lexer generators are ANTLR (ANother Tool for Language Recognition) and Lex.
Technically, we can use the built-in regex matcher to build a lexer, but that will be very inefficient.
Setting up ANTLR
We will use ANTLR to create a lexer which will tokenize the script that contains our custom code.
-
Install Java (version 1.6 or higher)
- Download the Java binaries
$ cd /usr/local/lib $ curl -O http://www.antlr.org/download/antlr-4.6-complete.jar - Add antlr-4.6-complete.jar to your CLASSPATH:
$ export CLASSPATH=".:/usr/local/lib/antlr-4.6-complete.jar:$CLASSPATH" - Create aliases for the ANTLR Tool, and TestRig.
$ alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.6-complete.jar:$CLASSPATH" org.antlr.v4.Tool' $ alias grun='java org.antlr.v4.gui.TestRig' - Check if antlr4 is configured properly.
Defining the grammar
We have a script (sample.script) that looks like this and we want to tokenize the whole code:
Observe that we have the following:
- Strings:
func,morning,@name,"Jay", … - Opening/closing angle brackets:
<,> - Equals:
= - Assignment operators:
:= - Semicolons:
; - Whitespaces and comments which begin with
//
In our grammar file, say ScriptLexer.g4, we have:
We can think of the file above as the “vocabulary” for our tokens. These lexer rules are based on regular expressions. More information can be found here.
.g4is the extension used for ANTLR v4 grammar files
Generating the lexer
Now that we have our grammar file, we can run the ANTLR tool on it to generate our lexer program.
$ antlr4 ScriptLexer.g4
This will generate two files: ScriptLexer.java (the code which contains the implementation of the FSM together with our token constants) and ScriptLexer.tokens. Now we will create a Java program to test our lexer: TestLexer.java
We then compile our test program.
$ javac TestLexer.java
And if we try to run TestLexer and giving sample.script as an argument, we get the following:
$ java TestLexer sample.script
Parsing: sample.script
STRING func
STRING morning
LPAREN <
STRING name
ASSIGN :=
STRING "Jay"
SEMICO ;
STRING greet
STRING morning
EQUALS =
STRING true
STRING input
EQUALS =
STRING @name
SEMICO ;
STRING eat
STRING cereals
SEMICO ;
STRING attend
STRING class
EQUALS =
STRING "CS101"
SEMICO ;
RPAREN >
STRING func
STRING night
LPAREN <
STRING brush_teeth
SEMICO ;
STRING sleep
STRING hours
EQUALS =
STRING 8
SEMICO ;
RPAREN >
We are done with lexical analysis. The lexer will match any valid characters that we have defined in the grammar and produce tokens. However, we did not enforce any rules on the syntax. Technically speaking, our lexer will tokenize a string like ;;;;>>>>><<<<<a>
but not a string like $%^ because we did not define any of those three characters %, %, and ^ in the grammar that the lexer takes in.
This is where a parser comes in. We need to define rules that defines a valid script through syntax analysis.
Going back to the SQL query parser that I was trying to build, surprisingly someone has already created an ANTLR4 grammar file for SQLite: https://github.com/bkiers/sqlite-parser.
Now moving on to the parser…
References:
- http://csfieldguide.org.nz/en/chapters/formal-languages.html
- https://github.com/antlr/antlr4/blob/master/doc/getting-started.md
- http://stackoverflow.com/questions/2842809/lexers-vs-parsers
- https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm
- https://github.com/antlr/grammars-v4
- Compilers: Principles, Techniques, and Tools (2nd Edition), also known as “the dragon book”
- http://puredanger.github.io/tech.puredanger.com/2007/01/13/implementing-a-scripting-language-with-antlr-part-1-lexer/